Build a linear model
library(tidymodels)
library(tidyverse)
library(rcfss)
library(rstanarm)
library(broom.mixed)
set.seed(123)
theme_set(theme_minimal())
Introduction
There are several different approaches to fitting a linear model in R.1 Here, we introduce tidymodels and demonstrate how to construct a basic linear regression model.
tidymodels is a collection of packages for statistical modeling and machine learning using tidyverse principles. Given this emphasis, it pairs nicely with the tidy-centric approach we have covered so far for tasks such as data visualization, data wrangling, importation of data files, and publishing results.
tidymodels is still under active development and contains a range of packages and functions for many different aspects of statistical modeling. Here we demonstrate how to start with data for modeling, specify and train models using different engines using the parsnip package, and understand why these functions are designed this way.
scorecard
As in past exercises, let’s use the rcfss::scorecard dataset which contains detailed information on all four-year colleges and universities in the United States. Here we will consider the average faculty salary to understand how it is influenced by factors such as the average annual total cost of attendance and whether the university is public, private nonprofit, or private for-profit.
scorecard
## # A tibble: 1,753 x 15
## unitid name state type admrate satavg cost netcost avgfacsal pctpell
## <int> <chr> <chr> <fct> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 420325 Yesh… NY Priv… 0.531 NA 14874 4018 26253 0.958
## 2 430485 The … NE Priv… 0.667 NA 41627 39020 54000 0.529
## 3 100654 Alab… AL Publ… 0.899 957 22489 14444 63909 0.707
## 4 102234 Spri… AL Priv… 0.658 1130 51969 19718 60048 0.342
## 5 100724 Alab… AL Publ… 0.977 972 21476 13043 69786 0.745
## 6 106467 Arka… AR Publ… 0.902 NA 18627 12362 61497 0.396
## 7 106704 Univ… AR Publ… 0.911 1186 21350 14723 63360 0.430
## 8 109651 Art … CA Priv… 0.676 NA 64097 43010 69984 0.307
## 9 110404 Cali… CA Priv… 0.0662 1566 68901 23820 179937 0.142
## 10 112394 Cogs… CA Priv… 0.579 NA 35351 31537 66636 0.461
## # … with 1,743 more rows, and 5 more variables: comprate <dbl>, firstgen <dbl>,
## # debt <dbl>, locale <fct>, openadmp <fct>
glimpse(scorecard)
## Rows: 1,753
## Columns: 15
## $ unitid <int> 420325, 430485, 100654, 102234, 100724, 106467, 106704, 109…
## $ name <chr> "Yeshiva D'monsey Rabbinical College", "The Creative Center…
## $ state <chr> "NY", "NE", "AL", "AL", "AL", "AR", "AR", "CA", "CA", "CA",…
## $ type <fct> "Private, nonprofit", "Private, for-profit", "Public", "Pri…
## $ admrate <dbl> 0.5313, 0.6667, 0.8986, 0.6577, 0.9774, 0.9024, 0.9110, 0.6…
## $ satavg <dbl> NA, NA, 957, 1130, 972, NA, 1186, NA, 1566, NA, NA, 1053, 1…
## $ cost <int> 14874, 41627, 22489, 51969, 21476, 18627, 21350, 64097, 689…
## $ netcost <dbl> 4018, 39020, 14444, 19718, 13043, 12362, 14723, 43010, 2382…
## $ avgfacsal <dbl> 26253, 54000, 63909, 60048, 69786, 61497, 63360, 69984, 179…
## $ pctpell <dbl> 0.9583, 0.5294, 0.7067, 0.3420, 0.7448, 0.3955, 0.4298, 0.3…
## $ comprate <dbl> 0.6667, 0.6667, 0.2685, 0.5864, 0.3001, 0.4069, 0.4113, 0.7…
## $ firstgen <dbl> NA, NA, 0.3658281, 0.2516340, 0.3434343, 0.4574780, 0.34595…
## $ debt <dbl> NA, 12000, 15500, 18270, 18679, 12000, 13100, 27811, 8013, …
## $ locale <fct> Suburb, City, City, City, City, Town, City, City, City, Cit…
## $ openadmp <fct> No, No, No, No, No, No, No, No, No, No, No, No, No, No, No,…
As a first step in modeling, it’s always a good idea to plot the data:
ggplot(
data = scorecard,
mapping = aes(
x = cost,
y = avgfacsal,
col = type
)
) +
geom_point(alpha = .3) +
geom_smooth(method = lm, se = FALSE) +
scale_color_viridis_d(option = "plasma", end = .7)
## `geom_smooth()` using formula 'y ~ x'
## Warning: Removed 52 rows containing non-finite values (stat_smooth).
## Warning: Removed 52 rows containing missing values (geom_point).
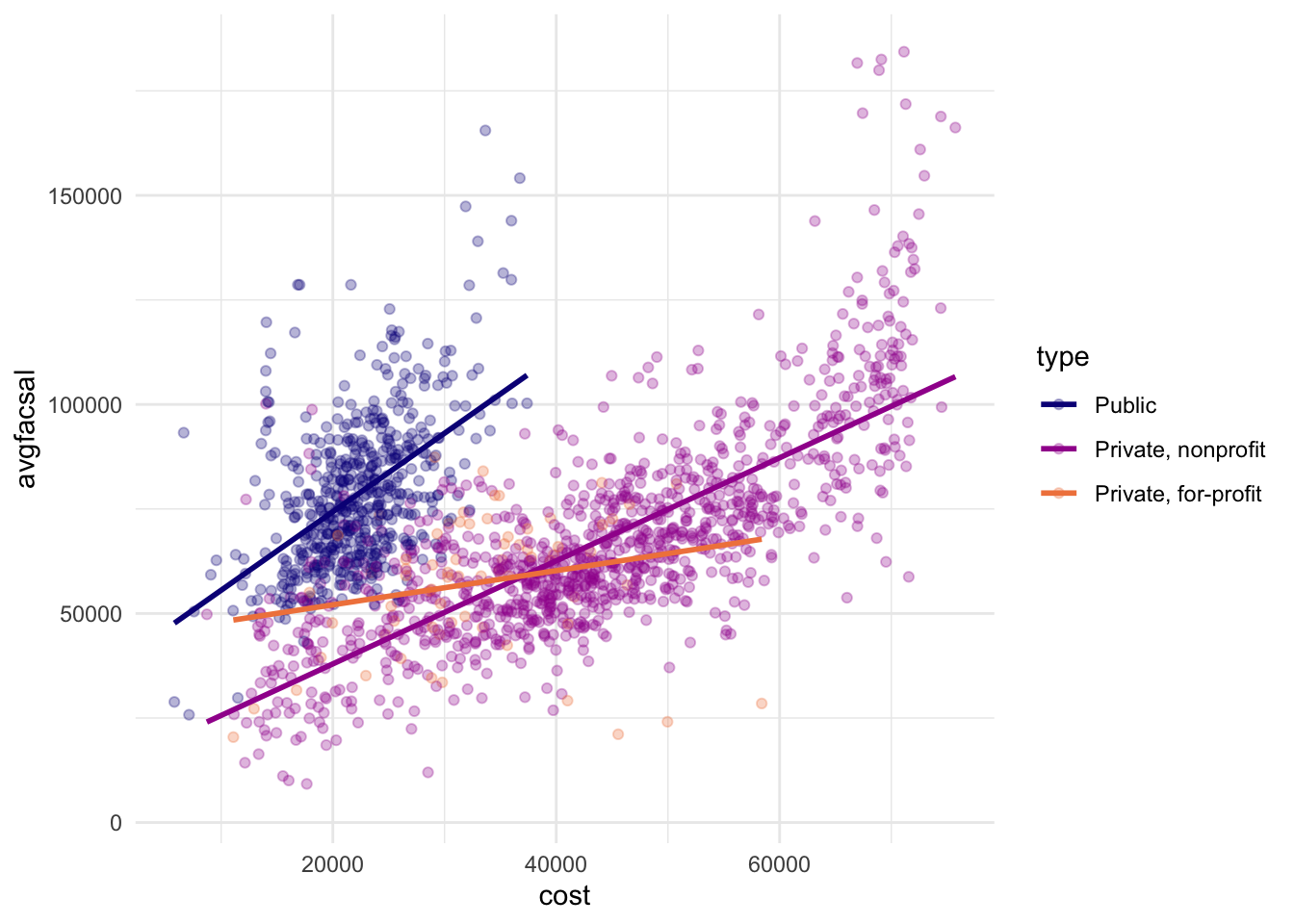
We can see that public and private non-profit schools have the strongest correlation between total cost of attendance and average faculty salaries – private for-profit schools tend to be pretty flat in terms of average salaries regardless of cost of attendance.
Build and fit a model
A standard two-way analysis of variance (ANOVA) model makes sense for this dataset because we have both a continuous predictor and a categorical predictor. Since the slopes appear to be different for at least two of the college types, let’s build a model that allows for two-way interactions. Specifying an R formula with our variables in this way:
avgfacsal ~ cost * type
allows our regression model depending on cost to have separate slopes and intercepts for each type of college.
For this kind of model, ordinary least squares is a good initial approach. With tidymodels, we start by specifying the functional form of the model that we want using the parsnip package. Since there is a numeric outcome and the model should be linear with slopes and intercepts, the model type is “linear regression”. We can declare this with:
linear_reg()
## Linear Regression Model Specification (regression)
That is pretty underwhelming since, on its own, it doesn’t really do much. However, now that the type of model has been specified, a method for fitting or training the model can be stated using the engine. The engine value is often a mash-up of the software that can be used to fit or train the model as well as the estimation method. For example, to use ordinary least squares, we can set the engine to be lm:
linear_reg() %>%
set_engine("lm")
## Linear Regression Model Specification (regression)
##
## Computational engine: lm
The documentation page for linear_reg() lists the possible engines. We’ll save this model object as lm_mod.

lm_mod <- linear_reg() %>%
set_engine("lm")
From here, the model can be estimated or trained using the fit() function:
lm_fit <- lm_mod %>%
fit(avgfacsal ~ cost * type, data = scorecard)
lm_fit
## parsnip model object
##
## Fit time: 4ms
##
## Call:
## stats::lm(formula = avgfacsal ~ cost * type, data = data)
##
## Coefficients:
## (Intercept) cost
## 3.678e+04 1.878e+00
## typePrivate, nonprofit typePrivate, for-profit
## -2.349e+04 7.121e+03
## cost:typePrivate, nonprofit cost:typePrivate, for-profit
## -6.453e-01 -1.469e+00
Perhaps our analysis requires a description of the model parameter estimates and their statistical properties. Although the summary() function for lm objects can provide that, it gives the results back in an unwieldy format. Many models have a tidy() method that provides the summary results in a more predictable and useful format (e.g. a data frame with standard column names):
tidy(lm_fit)
## # A tibble: 6 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 36782. 3178. 11.6 7.18e-30
## 2 cost 1.88 0.140 13.4 6.60e-39
## 3 typePrivate, nonprofit -23489. 3509. -6.69 2.93e-11
## 4 typePrivate, for-profit 7121. 7930. 0.898 3.69e- 1
## 5 cost:typePrivate, nonprofit -0.645 0.144 -4.48 7.85e- 6
## 6 cost:typePrivate, for-profit -1.47 0.256 -5.74 1.11e- 8
Use a model to predict
This fitted object lm_fit has the lm model output built-in, which you can access with lm_fit$fit, but there are some benefits to using the fitted parsnip model object when it comes to predicting.
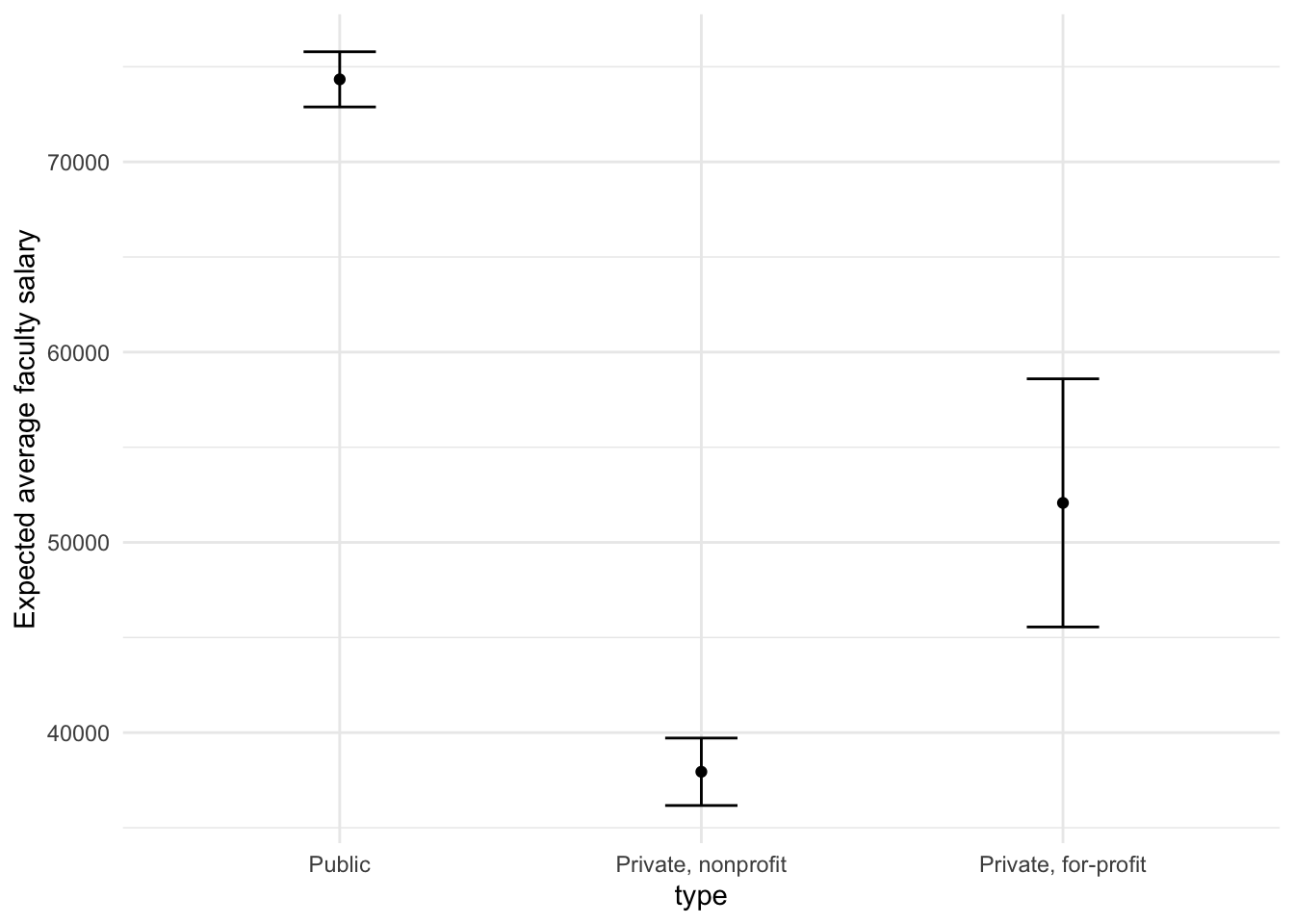
Suppose that, for a publication, it would be particularly interesting to make a plot of the expected average faculty salary for colleges with a total cost of attendance of $20,000. To create such a graph, we start with some new example data that we will make predictions for, to show in our graph:
new_points <- expand.grid(
cost = 20000,
type = c("Public", "Private, nonprofit", "Private, for-profit")
)
new_points
## cost type
## 1 20000 Public
## 2 20000 Private, nonprofit
## 3 20000 Private, for-profit
To get our predicted results, we can use the predict() function to find the expected salaries at $20,000 cost of attendance.
It is also important to communicate the variability, so we also need to find the predicted confidence intervals. If we had used lm() to fit the model directly, a few minutes of reading the documentation page for predict.lm() would explain how to do this. However, if we decide to use a different model to estimate average faculty salaries (spoiler: we will!), it is likely that a completely different syntax would be required.
Instead, with tidymodels, the types of predicted values are standardized so that we can use the same syntax to get these values.
First, let’s generate the expected salary values:
mean_pred <- predict(lm_fit, new_data = new_points)
mean_pred
## # A tibble: 3 x 1
## .pred
## <dbl>
## 1 74337.
## 2 37943.
## 3 52075.
When making predictions, the tidymodels convention is to always produce a tibble of results with standardized column names. This makes it easy to combine the original data and the predictions in a usable format:
conf_int_pred <- predict(lm_fit,
new_data = new_points,
type = "conf_int"
)
conf_int_pred
## # A tibble: 3 x 2
## .pred_lower .pred_upper
## <dbl> <dbl>
## 1 72886. 75788.
## 2 36170. 39715.
## 3 45553. 58597.
# Now combine
plot_data <- new_points %>%
bind_cols(mean_pred) %>%
bind_cols(conf_int_pred)
# And plot
ggplot(data = plot_data, mapping = aes(x = type)) +
geom_point(mapping = aes(y = .pred)) +
geom_errorbar(
mapping = aes(
ymin = .pred_lower,
ymax = .pred_upper
),
width = .2
) +
labs(y = "Expected average faculty salary")
Model with a different engine
Every one on your team is happy with that plot except that one person who just read their first book on Bayesian analysis. They are interested in knowing if the results would be different if the model were estimated using a Bayesian approach. In such an analysis, a prior distribution needs to be declared for each model parameter that represents the possible values of the parameters (before being exposed to the observed data). After some discussion, the group agrees that the priors should be bell-shaped but, since no one has any idea what the range of values should be, to take a conservative approach and make the priors wide using a Cauchy distribution (which is the same as a t-distribution with a single degree of freedom).
The documentation on the rstanarm package shows us that the stan_glm() function can be used to estimate this model, and that the function arguments that need to be specified are called prior and prior_intercept. It turns out that linear_reg() has a stan engine. Since these prior distribution arguments are specific to the Stan software, they are passed as arguments to parsnip::set_engine(). After that, the same exact fit() call is used:
# set the prior distribution
prior_dist <- rstanarm::student_t(df = 1)
set.seed(123)
# make the parsnip model
bayes_mod <- linear_reg() %>%
set_engine("stan",
prior_intercept = prior_dist,
prior = prior_dist,
# increase number of iterations to converge to stable solution
iter = 4000
)
# train the model
bayes_fit <- bayes_mod %>%
fit(avgfacsal ~ cost * type, data = scorecard)
print(bayes_fit, digits = 5)
## parsnip model object
##
## Fit time: 30s
## stan_glm
## family: gaussian [identity]
## formula: avgfacsal ~ cost * type
## observations: 1701
## predictors: 6
## ------
## Median MAD_SD
## (Intercept) 36248.11865 2992.28884
## cost 1.89989 0.13269
## typePrivate, nonprofit -22476.17585 3394.23724
## typePrivate, for-profit -0.00631 3.71628
## cost:typePrivate, nonprofit -0.67817 0.13872
## cost:typePrivate, for-profit -1.27142 0.07697
##
## Auxiliary parameter(s):
## Median MAD_SD
## sigma 15839.43907 274.49064
##
## ------
## * For help interpreting the printed output see ?print.stanreg
## * For info on the priors used see ?prior_summary.stanreg
set.seed() to ensure that the same (pseudo-)random numbers are generated each time we run this code. The number 123 isn’t special or related to our data; it is just a “seed” used to choose random numbers.To update the parameter table, the tidy() method is once again used:
tidy(bayes_fit, conf.int = TRUE)
## # A tibble: 6 x 5
## term estimate std.error conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 36248. 2992. 31363. 41235.
## 2 cost 1.90 0.133 1.68 2.11
## 3 typePrivate, nonprofit -22476. 3394. -28139. -16884.
## 4 typePrivate, for-profit -0.00631 3.72 -14.7 15.1
## 5 cost:typePrivate, nonprofit -0.678 0.139 -0.903 -0.449
## 6 cost:typePrivate, for-profit -1.27 0.0770 -1.40 -1.15
A goal of the tidymodels packages is that the interfaces to common tasks are standardized (as seen in the tidy() results above). The same is true for getting predictions; we can use the same code even though the underlying packages use very different syntax:
bayes_plot_data <- new_points %>%
bind_cols(predict(bayes_fit, new_data = new_points)) %>%
bind_cols(predict(bayes_fit, new_data = new_points, type = "conf_int"))
ggplot(data = bayes_plot_data, mapping = aes(x = type)) +
geom_point(mapping = aes(y = .pred)) +
geom_errorbar(
mapping = aes(
ymin = .pred_lower,
ymax = .pred_upper
),
width = .2
) +
labs(y = "Expected average faculty salary")
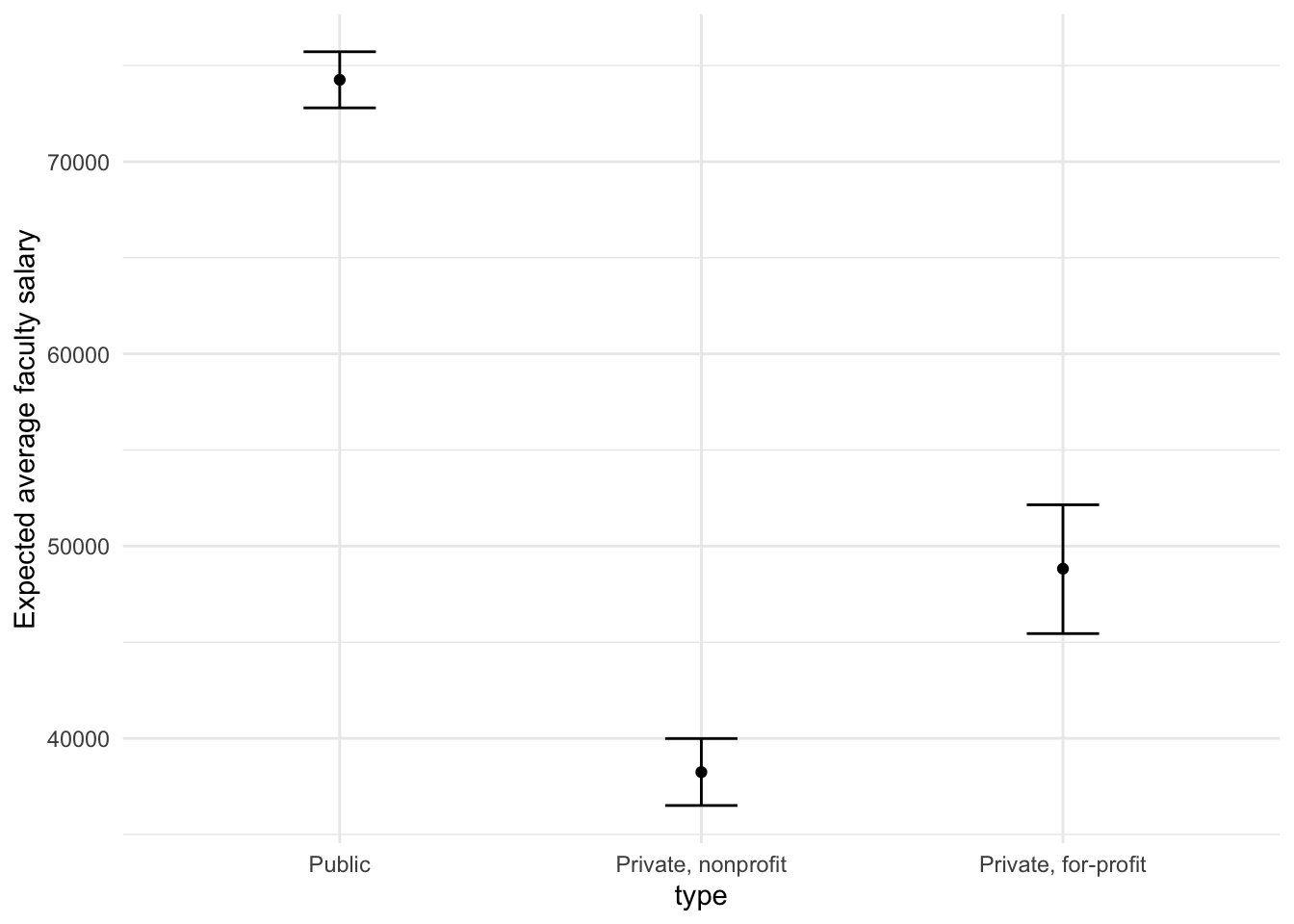
This isn’t very different from the non-Bayesian results (except in interpretation).
parsnip package can work with many model types, engines, and arguments. Check out tidymodels.org/find/parsnip/ to see what is available.Why does it work that way?
The extra step of defining the model using a function like linear_reg() might seem superfluous since a call to lm() is much more succinct. However, the problem with standard modeling functions is that they don’t separate what you want to do from the execution. For example, the process of executing a formula has to happen repeatedly across model calls even when the formula does not change; we can’t recycle those computations.
Also, using the tidymodels framework, we can do some interesting things by incrementally creating a model (instead of using single function call). Model tuning with tidymodels uses the specification of the model to declare what parts of the model should be tuned. That would be very difficult to do if linear_reg() immediately fit the model.
Acknowledgments
- Example drawn from Get Started - Build a model and licensed under CC BY-SA 4.0.
- Artwork by @allison_horst
Session Info
devtools::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.4 (2021-02-15)
## os macOS Big Sur 10.16
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/Chicago
## date 2021-05-25
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
## backports 1.2.1 2020-12-09 [1] CRAN (R 4.0.2)
## base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.0.0)
## bayesplot 1.8.0 2021-01-10 [1] CRAN (R 4.0.2)
## blogdown 1.3 2021-04-14 [1] CRAN (R 4.0.2)
## bookdown 0.22 2021-04-22 [1] CRAN (R 4.0.2)
## boot 1.3-28 2021-05-03 [1] CRAN (R 4.0.2)
## broom * 0.7.6 2021-04-05 [1] CRAN (R 4.0.4)
## broom.mixed * 0.2.6 2020-05-17 [1] CRAN (R 4.0.2)
## bslib 0.2.5 2021-05-12 [1] CRAN (R 4.0.4)
## cachem 1.0.5 2021-05-15 [1] CRAN (R 4.0.2)
## callr 3.7.0 2021-04-20 [1] CRAN (R 4.0.2)
## cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
## class 7.3-19 2021-05-03 [1] CRAN (R 4.0.2)
## cli 2.5.0 2021-04-26 [1] CRAN (R 4.0.2)
## coda 0.19-4 2020-09-30 [1] CRAN (R 4.0.2)
## codetools 0.2-18 2020-11-04 [1] CRAN (R 4.0.4)
## colorspace 2.0-1 2021-05-04 [1] CRAN (R 4.0.2)
## colourpicker 1.1.0 2020-09-14 [1] CRAN (R 4.0.2)
## crayon 1.4.1 2021-02-08 [1] CRAN (R 4.0.2)
## crosstalk 1.1.1 2021-01-12 [1] CRAN (R 4.0.2)
## curl 4.3.1 2021-04-30 [1] CRAN (R 4.0.2)
## DBI 1.1.1 2021-01-15 [1] CRAN (R 4.0.2)
## dbplyr 2.1.1 2021-04-06 [1] CRAN (R 4.0.4)
## desc 1.3.0 2021-03-05 [1] CRAN (R 4.0.2)
## devtools 2.4.1 2021-05-05 [1] CRAN (R 4.0.2)
## dials * 0.0.9 2020-09-16 [1] CRAN (R 4.0.2)
## DiceDesign 1.9 2021-02-13 [1] CRAN (R 4.0.2)
## digest 0.6.27 2020-10-24 [1] CRAN (R 4.0.2)
## dplyr * 1.0.6 2021-05-05 [1] CRAN (R 4.0.2)
## DT 0.18 2021-04-14 [1] CRAN (R 4.0.2)
## dygraphs 1.1.1.6 2018-07-11 [1] CRAN (R 4.0.0)
## ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.0.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
## fansi 0.4.2 2021-01-15 [1] CRAN (R 4.0.2)
## fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.0.2)
## forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.0.2)
## foreach 1.5.1 2020-10-15 [1] CRAN (R 4.0.2)
## fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.2)
## furrr 0.2.2 2021-01-29 [1] CRAN (R 4.0.2)
## future 1.21.0 2020-12-10 [1] CRAN (R 4.0.2)
## generics 0.1.0 2020-10-31 [1] CRAN (R 4.0.2)
## ggplot2 * 3.3.3 2020-12-30 [1] CRAN (R 4.0.2)
## ggridges 0.5.3 2021-01-08 [1] CRAN (R 4.0.2)
## globals 0.14.0 2020-11-22 [1] CRAN (R 4.0.2)
## glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
## gower 0.2.2 2020-06-23 [1] CRAN (R 4.0.2)
## GPfit 1.0-8 2019-02-08 [1] CRAN (R 4.0.0)
## gridExtra 2.3 2017-09-09 [1] CRAN (R 4.0.0)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
## gtools 3.8.2 2020-03-31 [1] CRAN (R 4.0.0)
## haven 2.4.1 2021-04-23 [1] CRAN (R 4.0.2)
## here 1.0.1 2020-12-13 [1] CRAN (R 4.0.2)
## hms 1.1.0 2021-05-17 [1] CRAN (R 4.0.4)
## htmltools 0.5.1.1 2021-01-22 [1] CRAN (R 4.0.2)
## htmlwidgets 1.5.3 2020-12-10 [1] CRAN (R 4.0.2)
## httpuv 1.6.1 2021-05-07 [1] CRAN (R 4.0.2)
## httr 1.4.2 2020-07-20 [1] CRAN (R 4.0.2)
## igraph 1.2.6 2020-10-06 [1] CRAN (R 4.0.2)
## infer * 0.5.4 2021-01-13 [1] CRAN (R 4.0.2)
## inline 0.3.18 2021-05-18 [1] CRAN (R 4.0.4)
## ipred 0.9-11 2021-03-12 [1] CRAN (R 4.0.2)
## iterators 1.0.13 2020-10-15 [1] CRAN (R 4.0.2)
## jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.0.2)
## jsonlite 1.7.2 2020-12-09 [1] CRAN (R 4.0.2)
## knitr 1.33 2021-04-24 [1] CRAN (R 4.0.2)
## later 1.2.0 2021-04-23 [1] CRAN (R 4.0.2)
## lattice 0.20-44 2021-05-02 [1] CRAN (R 4.0.2)
## lava 1.6.9 2021-03-11 [1] CRAN (R 4.0.2)
## lhs 1.1.1 2020-10-05 [1] CRAN (R 4.0.2)
## lifecycle 1.0.0 2021-02-15 [1] CRAN (R 4.0.2)
## listenv 0.8.0 2019-12-05 [1] CRAN (R 4.0.0)
## lme4 1.1-27 2021-05-15 [1] CRAN (R 4.0.2)
## loo 2.4.1 2020-12-09 [1] CRAN (R 4.0.2)
## lubridate 1.7.10 2021-02-26 [1] CRAN (R 4.0.2)
## magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.0.2)
## markdown 1.1 2019-08-07 [1] CRAN (R 4.0.0)
## MASS 7.3-54 2021-05-03 [1] CRAN (R 4.0.2)
## Matrix 1.3-3 2021-05-04 [1] CRAN (R 4.0.2)
## matrixStats 0.58.0 2021-01-29 [1] CRAN (R 4.0.2)
## memoise 2.0.0 2021-01-26 [1] CRAN (R 4.0.2)
## mime 0.10 2021-02-13 [1] CRAN (R 4.0.2)
## miniUI 0.1.1.1 2018-05-18 [1] CRAN (R 4.0.0)
## minqa 1.2.4 2014-10-09 [1] CRAN (R 4.0.0)
## modeldata * 0.1.0 2020-10-22 [1] CRAN (R 4.0.2)
## modelr 0.1.8 2020-05-19 [1] CRAN (R 4.0.0)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
## nlme 3.1-152 2021-02-04 [1] CRAN (R 4.0.4)
## nloptr 1.2.2.2 2020-07-02 [1] CRAN (R 4.0.2)
## nnet 7.3-16 2021-05-03 [1] CRAN (R 4.0.2)
## parallelly 1.25.0 2021-04-30 [1] CRAN (R 4.0.2)
## parsnip * 0.1.5 2021-01-19 [1] CRAN (R 4.0.2)
## pillar 1.6.1 2021-05-16 [1] CRAN (R 4.0.4)
## pkgbuild 1.2.0 2020-12-15 [1] CRAN (R 4.0.2)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
## pkgload 1.2.1 2021-04-06 [1] CRAN (R 4.0.2)
## plyr 1.8.6 2020-03-03 [1] CRAN (R 4.0.0)
## prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
## pROC 1.17.0.1 2021-01-13 [1] CRAN (R 4.0.2)
## processx 3.5.2 2021-04-30 [1] CRAN (R 4.0.2)
## prodlim 2019.11.13 2019-11-17 [1] CRAN (R 4.0.0)
## promises 1.2.0.1 2021-02-11 [1] CRAN (R 4.0.2)
## ps 1.6.0 2021-02-28 [1] CRAN (R 4.0.2)
## purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
## R6 2.5.0 2020-10-28 [1] CRAN (R 4.0.2)
## rcfss * 0.2.1 2020-12-08 [1] local
## Rcpp * 1.0.6 2021-01-15 [1] CRAN (R 4.0.2)
## RcppParallel 5.1.4 2021-05-04 [1] CRAN (R 4.0.2)
## readr * 1.4.0 2020-10-05 [1] CRAN (R 4.0.2)
## readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
## recipes * 0.1.16 2021-04-16 [1] CRAN (R 4.0.2)
## remotes 2.3.0 2021-04-01 [1] CRAN (R 4.0.2)
## reprex 2.0.0 2021-04-02 [1] CRAN (R 4.0.2)
## reshape2 1.4.4 2020-04-09 [1] CRAN (R 4.0.0)
## rlang 0.4.11 2021-04-30 [1] CRAN (R 4.0.2)
## rmarkdown 2.8 2021-05-07 [1] CRAN (R 4.0.2)
## rpart 4.1-15 2019-04-12 [1] CRAN (R 4.0.4)
## rprojroot 2.0.2 2020-11-15 [1] CRAN (R 4.0.2)
## rsample * 0.1.0 2021-05-08 [1] CRAN (R 4.0.2)
## rsconnect 0.8.17 2021-04-09 [1] CRAN (R 4.0.2)
## rstan 2.21.1 2020-07-08 [1] CRAN (R 4.0.2)
## rstanarm * 2.21.1 2020-07-20 [1] CRAN (R 4.0.2)
## rstantools 2.1.1 2020-07-06 [1] CRAN (R 4.0.2)
## rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.0.2)
## rvest 1.0.0 2021-03-09 [1] CRAN (R 4.0.2)
## sass 0.4.0 2021-05-12 [1] CRAN (R 4.0.2)
## scales * 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## shiny 1.6.0 2021-01-25 [1] CRAN (R 4.0.2)
## shinyjs 2.0.0 2020-09-09 [1] CRAN (R 4.0.2)
## shinystan 2.5.0 2018-05-01 [1] CRAN (R 4.0.0)
## shinythemes 1.2.0 2021-01-25 [1] CRAN (R 4.0.2)
## StanHeaders 2.21.0-7 2020-12-17 [1] CRAN (R 4.0.2)
## stringi 1.6.1 2021-05-10 [1] CRAN (R 4.0.2)
## stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
## survival 3.2-11 2021-04-26 [1] CRAN (R 4.0.2)
## testthat 3.0.2 2021-02-14 [1] CRAN (R 4.0.2)
## threejs 0.3.3 2020-01-21 [1] CRAN (R 4.0.0)
## tibble * 3.1.1 2021-04-18 [1] CRAN (R 4.0.2)
## tidymodels * 0.1.3 2021-04-19 [1] CRAN (R 4.0.2)
## tidyr * 1.1.3 2021-03-03 [1] CRAN (R 4.0.2)
## tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.0.2)
## tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.0.2)
## timeDate 3043.102 2018-02-21 [1] CRAN (R 4.0.0)
## TMB 1.7.20 2021-04-08 [1] CRAN (R 4.0.2)
## tune * 0.1.5 2021-04-23 [1] CRAN (R 4.0.2)
## usethis 2.0.1 2021-02-10 [1] CRAN (R 4.0.2)
## utf8 1.2.1 2021-03-12 [1] CRAN (R 4.0.2)
## V8 3.4.2 2021-05-01 [1] CRAN (R 4.0.2)
## vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.0.2)
## withr 2.4.2 2021-04-18 [1] CRAN (R 4.0.2)
## workflows * 0.2.2 2021-03-10 [1] CRAN (R 4.0.2)
## workflowsets * 0.0.2 2021-04-16 [1] CRAN (R 4.0.2)
## xfun 0.23 2021-05-15 [1] CRAN (R 4.0.2)
## xml2 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
## xtable 1.8-4 2019-04-21 [1] CRAN (R 4.0.0)
## xts 0.12.1 2020-09-09 [1] CRAN (R 4.0.2)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
## yardstick * 0.0.8 2021-03-28 [1] CRAN (R 4.0.2)
## zoo 1.8-9 2021-03-09 [1] CRAN (R 4.0.2)
##
## [1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library
- See Tidy Modeling with R for an overview of how these approaches vary. ^