Practicing tidytext with song titles
library(tidyverse)
library(acs)
library(tidytext)
library(here)
set.seed(1234)
theme_set(theme_minimal())
Run the code below in your console to download this exercise as a set of R scripts.
usethis::use_course("uc-cfss/text-analysis-fundamentals-and-sentiment-analysis")
Today let’s practice our tidytext skills with a basic analysis of song titles. That is, how often is each U.S. state mentioned in a popular song? We’ll define popular songs as those in Billboard’s Year-End Hot 100 from 1958 to the present.
Download population data for U.S. states
First let’s use the tidycensus package to access the U.S. Census Bureau API and obtain population numbers for each state in 2016. This will help us later to normalize state mentions based on relative population size.1
To import the data in-class, run:
pop_df <- read_csv("http://cfss.uchicago.edu/data/pop2016.csv")
The code below shows how the file was originally constructed.
# retrieve state populations in 2016 from Census Bureau ACS
library(tidycensus)
pop_df <- get_acs(
geography = "state", year = 2016,
variables = c(population = "B01003_001")
) %>%
# remove moe and tidy the data frame
select(-moe) %>%
spread(variable, estimate) %>%
# clean the data to match with the structure of the lyrics data
rename(state_name = NAME) %>%
mutate(state_name = str_to_lower(state_name)) %>%
filter(state_name != "Puerto Rico") %>%
write_csv(here("static", "data", "pop2016.csv"))
## Getting data from the 2012-2016 5-year ACS
# do these results make sense?
pop_df %>%
arrange(desc(population)) %>%
top_n(10)
## Selecting by population
## # A tibble: 10 x 3
## GEOID state_name population
## <chr> <chr> <dbl>
## 1 06 california 38654206
## 2 48 texas 26956435
## 3 12 florida 19934451
## 4 36 new york 19697457
## 5 17 illinois 12851684
## 6 42 pennsylvania 12783977
## 7 39 ohio 11586941
## 8 13 georgia 10099320
## 9 37 north carolina 9940828
## 10 26 michigan 9909600
Retrieve song lyrics
Next we need to retrieve the song lyrics for all our songs. Kaylin Walker provides a GitHub repo with the necessary files.
To import the data in-class, use
song_lyrics <- read_csv("http://cfss.uchicago.edu/data/billboard_lyrics_1964-2015.csv")
##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## Rank = col_double(),
## Song = col_character(),
## Artist = col_character(),
## Year = col_double(),
## Lyrics = col_character(),
## Source = col_double()
## )
## Rows: 5,100
## Columns: 6
## $ Rank <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,…
## $ Song <chr> "wooly bully", "i cant help myself sugar pie honey bunch", "i …
## $ Artist <chr> "sam the sham and the pharaohs", "four tops", "the rolling sto…
## $ Year <dbl> 1965, 1965, 1965, 1965, 1965, 1965, 1965, 1965, 1965, 1965, 19…
## $ Lyrics <chr> "sam the sham miscellaneous wooly bully wooly bully sam the sh…
## $ Source <dbl> 3, 1, 1, 1, 1, 1, 3, 5, 1, 3, 3, 1, 3, 1, 3, 3, 3, 3, 1, 1, 1,…
The lyrics are stored as character vectors, one string for each song. Consider the song Uptown Funk:
## this hit that ice cold michelle pfeiffer that white gold this one for them hood
## girls them good girls straight masterpieces stylin whilen livin it up in the
## city got chucks on with saint laurent got kiss myself im so prettyim too hot
## hot damn called a police and a fireman im too hot hot damn make a dragon wanna
## retire man im too hot hot damn say my name you know who i am im too hot hot damn
## am i bad bout that money break it downgirls hit your hallelujah whoo girls hit
## your hallelujah whoo girls hit your hallelujah whoo cause uptown funk gon give
## it to you cause uptown funk gon give it to you cause uptown funk gon give it
## to you saturday night and we in the spot dont believe me just watch come ondont
## believe me just watch uhdont believe me just watch dont believe me just watch
## dont believe me just watch dont believe me just watch hey hey hey oh meaning
## byamandah editor 70s girl group the sequence accused bruno mars and producer
## mark ronson of ripping their sound off in uptown funk their song in question is
## funk you see all stop wait a minute fill my cup put some liquor in it take a sip
## sign a check julio get the stretch ride to harlem hollywood jackson mississippi
## if we show up we gon show out smoother than a fresh jar of skippyim too hot
## hot damn called a police and a fireman im too hot hot damn make a dragon wanna
## retire man im too hot hot damn bitch say my name you know who i am im too hot
## hot damn am i bad bout that money break it downgirls hit your hallelujah whoo
## girls hit your hallelujah whoo girls hit your hallelujah whoo cause uptown funk
## gon give it to you cause uptown funk gon give it to you cause uptown funk gon
## give it to you saturday night and we in the spot dont believe me just watch
## come ondont believe me just watch uhdont believe me just watch uh dont believe
## me just watch uh dont believe me just watch dont believe me just watch hey hey
## hey ohbefore we leave lemmi tell yall a lil something uptown funk you up uptown
## funk you up uptown funk you up uptown funk you up uh i said uptown funk you up
## uptown funk you up uptown funk you up uptown funk you upcome on dance jump on
## it if you sexy then flaunt it if you freaky then own it dont brag about it come
## show mecome on dance jump on it if you sexy then flaunt it well its saturday
## night and we in the spot dont believe me just watch come ondont believe me just
## watch uhdont believe me just watch uh dont believe me just watch uh dont believe
## me just watch dont believe me just watch hey hey hey ohuptown funk you up uptown
## funk you up say what uptown funk you up uptown funk you up uptown funk you up
## uptown funk you up say what uptown funk you up uptown funk you up uptown funk
## you up uptown funk you up say what uptown funk you up uptown funk you up uptown
## funk you up uptown funk you up say what uptown funk you up
Find and visualize the state names in the song lyrics
Now your work begins!
Use tidytext to create a data frame with one row for each token in each song
Hint: To search for matching state names, this data frame should include both unigrams and bi-grams.
Click for the solution
# tokenize
lyrics_unigrams <- unnest_tokens(
tbl = song_lyrics,
output = word,
input = Lyrics
)
lyrics_bigrams <- unnest_tokens(
tbl = song_lyrics,
output = word,
input = Lyrics,
token = "ngrams", n = 2
)
# combine together
tidy_lyrics <- bind_rows(lyrics_unigrams, lyrics_bigrams)
tidy_lyrics
## # A tibble: 3,201,465 x 6
## Rank Song Artist Year Source word
## <dbl> <chr> <chr> <dbl> <dbl> <chr>
## 1 1 wooly bully sam the sham and the pharaohs 1965 3 sam
## 2 1 wooly bully sam the sham and the pharaohs 1965 3 the
## 3 1 wooly bully sam the sham and the pharaohs 1965 3 sham
## 4 1 wooly bully sam the sham and the pharaohs 1965 3 miscellaneous
## 5 1 wooly bully sam the sham and the pharaohs 1965 3 wooly
## 6 1 wooly bully sam the sham and the pharaohs 1965 3 bully
## 7 1 wooly bully sam the sham and the pharaohs 1965 3 wooly
## 8 1 wooly bully sam the sham and the pharaohs 1965 3 bully
## 9 1 wooly bully sam the sham and the pharaohs 1965 3 sam
## 10 1 wooly bully sam the sham and the pharaohs 1965 3 the
## # … with 3,201,455 more rows
The variable word in this data frame contains all the possible words and bigrams that might be state names in all the lyrics.
Find all the state names occurring in the song lyrics
First create a data frame that meets this criteria, then save a new data frame that only includes one observation for each matching song. That is, if the song is “New York, New York”, there should only be one row in the resulting table for that song.
Click for the solution
inner_join(tidy_lyrics, pop_df, by = c("word" = "state_name"))
## # A tibble: 526 x 8
## Rank Song Artist Year Source word GEOID population
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr> <dbl>
## 1 12 king of the road roger miller 1965 1 maine 23 1329923
## 2 29 eve of destructi… barry mcguire 1965 1 alabama 01 4841164
## 3 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 4 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 5 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 6 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 7 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 8 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 9 49 california girls the beach bo… 1965 3 californ… 06 38654206
## 10 49 california girls the beach bo… 1965 3 californ… 06 38654206
## # … with 516 more rows
Let’s only count each state once per song that it is mentioned in.
tidy_lyrics <- inner_join(tidy_lyrics, pop_df, by = c("word" = "state_name")) %>%
distinct(Rank, Song, Artist, Year, word, .keep_all = TRUE)
tidy_lyrics
## # A tibble: 253 x 8
## Rank Song Artist Year Source word GEOID population
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr> <dbl>
## 1 12 king of the road roger miller 1965 1 maine 23 1329923
## 2 29 eve of destruct… barry mcguire 1965 1 alabama 01 4841164
## 3 49 california girls the beach boys 1965 3 califo… 06 38654206
## 4 10 california drea… the mamas the … 1966 3 califo… 06 38654206
## 5 77 message to mich… dionne warwick 1966 1 kentuc… 21 4411989
## 6 61 california nigh… lesley gore 1967 1 califo… 06 38654206
## 7 4 sittin on the d… otis redding 1968 1 georgia 13 10099320
## 8 10 tighten up archie bell th… 1968 3 texas 48 26956435
## 9 25 get back the beatles wit… 1969 3 arizona 04 6728577
## 10 25 get back the beatles wit… 1969 3 califo… 06 38654206
## # … with 243 more rows
Calculate the frequency for each state’s mention in a song and create a new column for the frequency adjusted by the state’s population
Click for the solution
(state_counts <- tidy_lyrics %>%
count(word) %>%
arrange(desc(n)))
## # A tibble: 33 x 2
## word n
## <chr> <int>
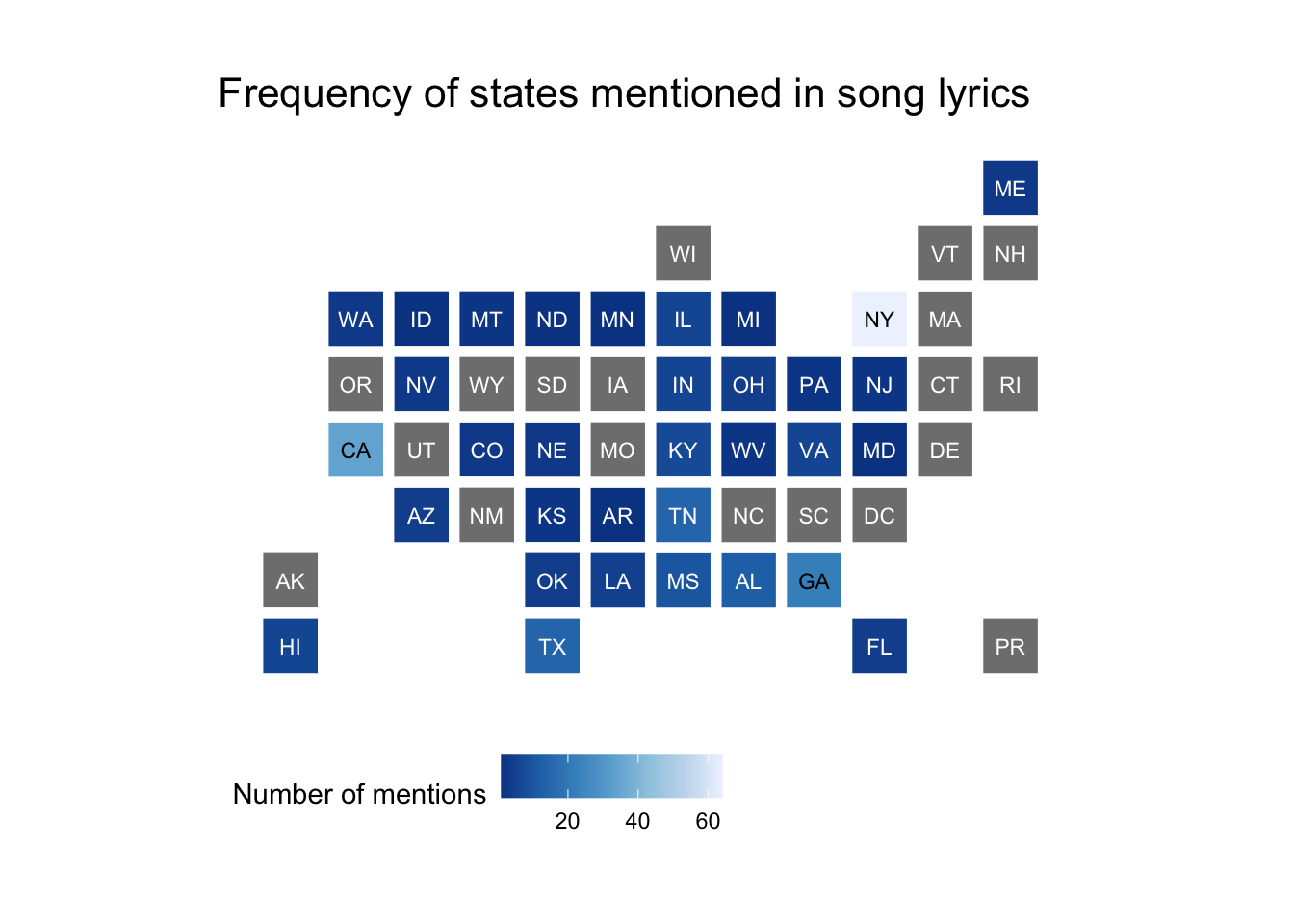
## 1 new york 64
## 2 california 34
## 3 georgia 22
## 4 tennessee 14
## 5 texas 14
## 6 alabama 12
## 7 mississippi 10
## 8 kentucky 7
## 9 hawaii 6
## 10 illinois 6
## # … with 23 more rows
pop_df <- pop_df %>%
left_join(state_counts, by = c("state_name" = "word")) %>%
mutate(rate = n / population * 1e6)
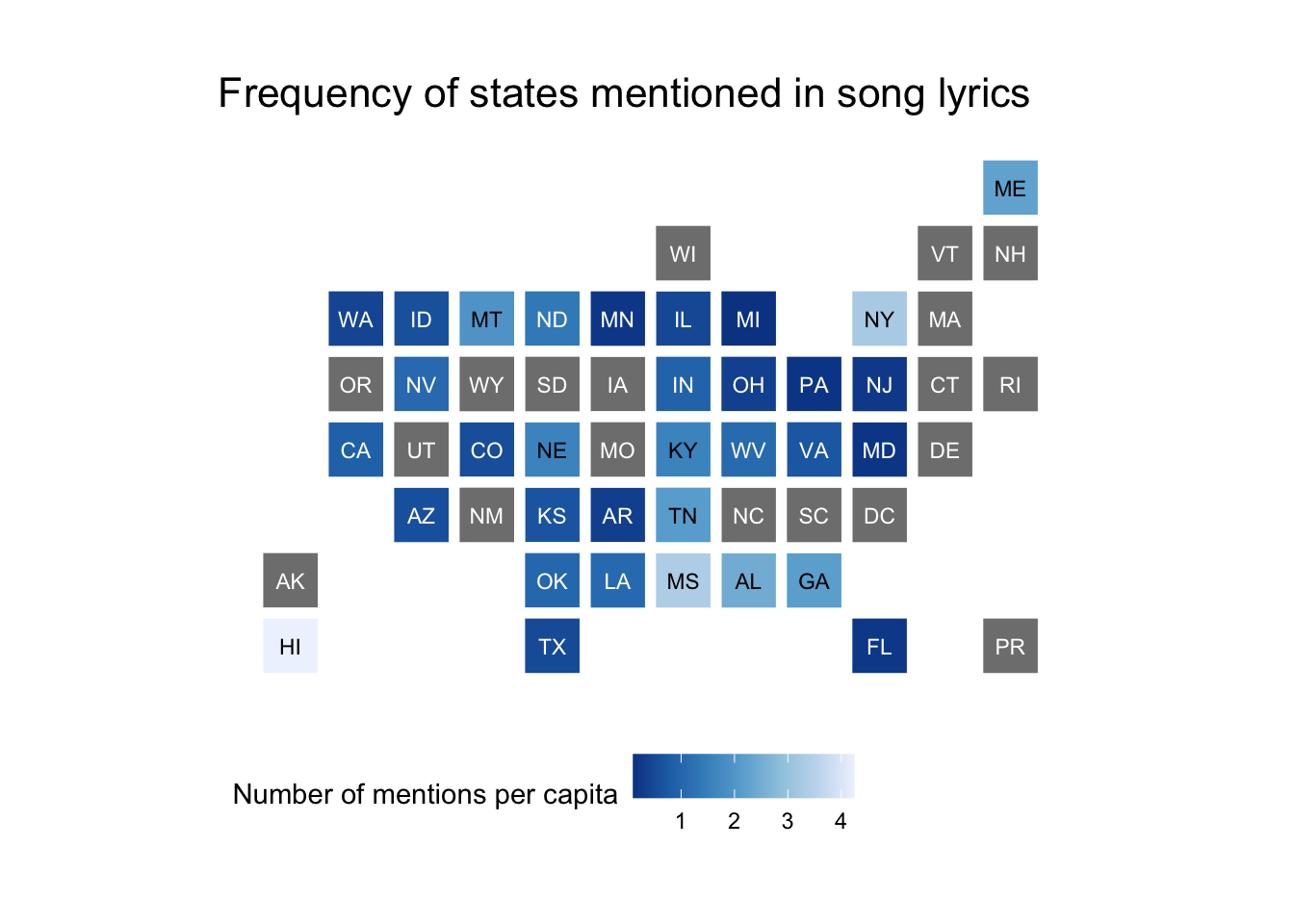
## which are the top ten states by rate?
pop_df %>%
arrange(desc(rate)) %>%
top_n(10)
## Selecting by rate
## # A tibble: 10 x 5
## GEOID state_name population n rate
## <chr> <chr> <dbl> <int> <dbl>
## 1 15 hawaii 1413673 6 4.24
## 2 28 mississippi 2989192 10 3.35
## 3 36 new york 19697457 64 3.25
## 4 01 alabama 4841164 12 2.48
## 5 23 maine 1329923 3 2.26
## 6 13 georgia 10099320 22 2.18
## 7 47 tennessee 6548009 14 2.14
## 8 30 montana 1023391 2 1.95
## 9 31 nebraska 1881259 3 1.59
## 10 21 kentucky 4411989 7 1.59
Make a choropleth map for both the raw frequency counts and relative frequency counts
The statebins package is a nifty shortcut for making basic U.S. cartogram maps.
library(statebins)
pop_df %>%
mutate(
state_name = stringr::str_to_title(state_name),
state_name = if_else(state_name == "District Of Columbia",
"District of Columbia", state_name
)
) %>%
statebins(
state_col = "state_name", value_col = "n",
name = "Number of mentions"
) +
labs(title = "Frequency of states mentioned in song lyrics") +
theme_statebins()
pop_df %>%
mutate(
state_name = stringr::str_to_title(state_name),
state_name = if_else(state_name == "District Of Columbia",
"District of Columbia", state_name
)
) %>%
statebins(
state_col = "state_name", value_col = "rate",
name = "Number of mentions per capita"
) +
labs(title = "Frequency of states mentioned in song lyrics") +
theme_statebins()
Acknowledgments
- This page is derived in part from SONG LYRICS ACROSS THE UNITED STATES and licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Session Info
devtools::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.4 (2021-02-15)
## os macOS Big Sur 10.16
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/Chicago
## date 2021-05-25
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## acs * 2.1.4 2019-02-19 [1] CRAN (R 4.0.0)
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
## backports 1.2.1 2020-12-09 [1] CRAN (R 4.0.2)
## blogdown 1.3 2021-04-14 [1] CRAN (R 4.0.2)
## bookdown 0.22 2021-04-22 [1] CRAN (R 4.0.2)
## broom 0.7.6 2021-04-05 [1] CRAN (R 4.0.4)
## bslib 0.2.5 2021-05-12 [1] CRAN (R 4.0.4)
## cachem 1.0.5 2021-05-15 [1] CRAN (R 4.0.2)
## callr 3.7.0 2021-04-20 [1] CRAN (R 4.0.2)
## cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
## cli 2.5.0 2021-04-26 [1] CRAN (R 4.0.2)
## colorspace 2.0-1 2021-05-04 [1] CRAN (R 4.0.2)
## crayon 1.4.1 2021-02-08 [1] CRAN (R 4.0.2)
## DBI 1.1.1 2021-01-15 [1] CRAN (R 4.0.2)
## dbplyr 2.1.1 2021-04-06 [1] CRAN (R 4.0.4)
## desc 1.3.0 2021-03-05 [1] CRAN (R 4.0.2)
## devtools 2.4.1 2021-05-05 [1] CRAN (R 4.0.2)
## digest 0.6.27 2020-10-24 [1] CRAN (R 4.0.2)
## dplyr * 1.0.6 2021-05-05 [1] CRAN (R 4.0.2)
## ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.0.2)
## evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
## fansi 0.4.2 2021-01-15 [1] CRAN (R 4.0.2)
## fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.0.2)
## forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.0.2)
## fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.2)
## generics 0.1.0 2020-10-31 [1] CRAN (R 4.0.2)
## ggplot2 * 3.3.3 2020-12-30 [1] CRAN (R 4.0.2)
## glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
## haven 2.4.1 2021-04-23 [1] CRAN (R 4.0.2)
## here * 1.0.1 2020-12-13 [1] CRAN (R 4.0.2)
## hms 1.1.0 2021-05-17 [1] CRAN (R 4.0.4)
## htmltools 0.5.1.1 2021-01-22 [1] CRAN (R 4.0.2)
## httr 1.4.2 2020-07-20 [1] CRAN (R 4.0.2)
## janeaustenr 0.1.5 2017-06-10 [1] CRAN (R 4.0.0)
## jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.0.2)
## jsonlite 1.7.2 2020-12-09 [1] CRAN (R 4.0.2)
## knitr 1.33 2021-04-24 [1] CRAN (R 4.0.2)
## lattice 0.20-44 2021-05-02 [1] CRAN (R 4.0.2)
## lifecycle 1.0.0 2021-02-15 [1] CRAN (R 4.0.2)
## lubridate 1.7.10 2021-02-26 [1] CRAN (R 4.0.2)
## magrittr 2.0.1 2020-11-17 [1] CRAN (R 4.0.2)
## Matrix 1.3-3 2021-05-04 [1] CRAN (R 4.0.2)
## memoise 2.0.0 2021-01-26 [1] CRAN (R 4.0.2)
## modelr 0.1.8 2020-05-19 [1] CRAN (R 4.0.0)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
## pillar 1.6.1 2021-05-16 [1] CRAN (R 4.0.4)
## pkgbuild 1.2.0 2020-12-15 [1] CRAN (R 4.0.2)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
## pkgload 1.2.1 2021-04-06 [1] CRAN (R 4.0.2)
## plyr 1.8.6 2020-03-03 [1] CRAN (R 4.0.0)
## prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
## processx 3.5.2 2021-04-30 [1] CRAN (R 4.0.2)
## ps 1.6.0 2021-02-28 [1] CRAN (R 4.0.2)
## purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
## R6 2.5.0 2020-10-28 [1] CRAN (R 4.0.2)
## Rcpp 1.0.6 2021-01-15 [1] CRAN (R 4.0.2)
## readr * 1.4.0 2020-10-05 [1] CRAN (R 4.0.2)
## readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
## remotes 2.3.0 2021-04-01 [1] CRAN (R 4.0.2)
## reprex 2.0.0 2021-04-02 [1] CRAN (R 4.0.2)
## rlang 0.4.11 2021-04-30 [1] CRAN (R 4.0.2)
## rmarkdown 2.8 2021-05-07 [1] CRAN (R 4.0.2)
## rprojroot 2.0.2 2020-11-15 [1] CRAN (R 4.0.2)
## rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.0.2)
## rvest 1.0.0 2021-03-09 [1] CRAN (R 4.0.2)
## sass 0.4.0 2021-05-12 [1] CRAN (R 4.0.2)
## scales 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## SnowballC 0.7.0 2020-04-01 [1] CRAN (R 4.0.0)
## stringi 1.6.1 2021-05-10 [1] CRAN (R 4.0.2)
## stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
## testthat 3.0.2 2021-02-14 [1] CRAN (R 4.0.2)
## tibble * 3.1.1 2021-04-18 [1] CRAN (R 4.0.2)
## tidyr * 1.1.3 2021-03-03 [1] CRAN (R 4.0.2)
## tidyselect 1.1.1 2021-04-30 [1] CRAN (R 4.0.2)
## tidytext * 0.3.1 2021-04-10 [1] CRAN (R 4.0.2)
## tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.0.2)
## tokenizers 0.2.1 2018-03-29 [1] CRAN (R 4.0.0)
## usethis 2.0.1 2021-02-10 [1] CRAN (R 4.0.2)
## utf8 1.2.1 2021-03-12 [1] CRAN (R 4.0.2)
## vctrs 0.3.8 2021-04-29 [1] CRAN (R 4.0.2)
## withr 2.4.2 2021-04-18 [1] CRAN (R 4.0.2)
## xfun 0.23 2021-05-15 [1] CRAN (R 4.0.2)
## XML * 3.99-0.6 2021-03-16 [1] CRAN (R 4.0.2)
## xml2 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
##
## [1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library
- For instance, California has a lot more people than Rhode Island so it makes sense that California would be mentioned more often in popular songs. But per capita, are these mentions different? ^